Start with Part 1 to learn how I captured 4000 photographs of the mostly-naked, mostly-painted Solstice Cyclists.
Inadequate spreadsheet
My naive start was a spreadsheet with columns for what people wore, what they rode, and a description of their paint. I used the row number of the spreadsheet as the cyclist ID & tagged images that contained a certain cyclist with that number. I had columns for top, bottom, head, and face clothing. That didn’t account for people wearing fairy wings, or sunglasses & a fake beard at the same time. Putting each piece of data in a separate column meant that I could search for “red” or for “sunglasses” but not for “red person wearing sunglasses” So the spreadsheet was not expressive enough to capture the information & search was inefficient, so dupe-checking took a long time.
Database design
Instead of giving each cyclists clothing slots that could have either 0 or 1 items in each, I created a many-to-many relationship between clothes and cyclists. Each piece of clothing also had a “slot” attribute (top, bottom head, face, back, or other). So a cyclist could wear any number of items, and each item would keep track of where it was worn. Cyclists & images also had a many-to-many relationship. Vehicle & Sex were simple enumerations. Descriptions remained as plain text.
Spreadsheet to database.
Converting all the data in the spreadsheet to DB records let me remove any inconsistencies in how I entered the data in the spreadsheet, e.g. “wig, blue” or “blue wig”. As I added clothes & vehicles to the DB, I searched & replaced those words in the spreadsheet with the DB IDs. I had to be careful to replace only words in the appropriate columns, since the plain-text descriptions sometimes referenced clothing or vehicles. Sometimes I missed and found a description like, “Mostly red, wearing a green 73” which is quite confusing.
Once I’d replaced all the words with database IDs, I exported the spreadsheet as a CSV file and wrote a PHP script to ingest it into the database. I chose PHP because I’ve already done a lot of SQL with PHP for my Atlanta Fashion Police & convention gallery projects. The script was pretty simple. The line number was the cyclist ID. The first column contains an ID for Table X, the second column contains an ID for Table Y, and so on. My PHP server has a maximum execution time of 30 seconds, so I added parameters to the script to only ingest 100 lines at a time and ran the script multiple times. Since it’s a private PHP server that doesn’t have consumer traffic, I should have just increased the timeout, let the script run, then changed it back.
While building the spreadsheet, I had been tagging photographs in Lightroom with cyclist IDs. I exported the tagged photographs into a certain directory, then wrote another PHP script to iterate through all files in that directory, read the EXIF data, and fill in the images_show_cyclists table.
New frontend
This is my process for identifying cyclists going forward. I look at an image in Lightroom and find a new cyclist who was not in the previous image. I may scrub back and forth in the timeline to get a better view. I fill in the search/create page to see if I have already seen a similar cyclist.
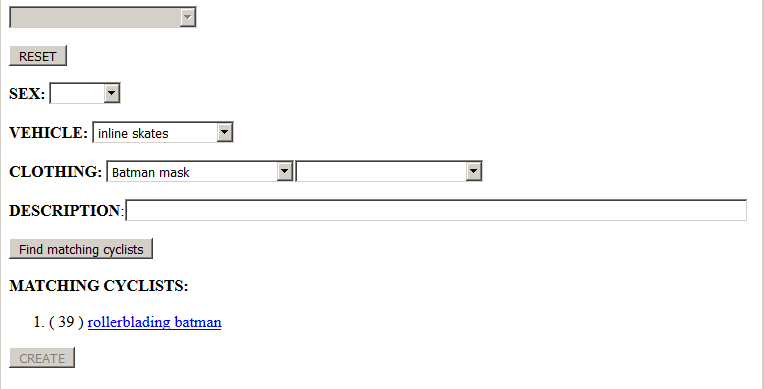
New “clothing” dropdowns are created as existing ones are filled in, so I can specify any number of clothing items. The “description” field checks for each word in order, so “blue yellow” matches both “blue & yellow stripes on arms” and “blue torso, red arms, black legs, goofy hat, yellow face”
Clicking “Find matching cyclists” will either show a list of cyclists with the features I’ve selected, or unlock the “CREATE” button if there are no matching cyclists. Each matching cyclist is a link that takes me to a page that lists its features, what images it appears in, and previews one of those images.
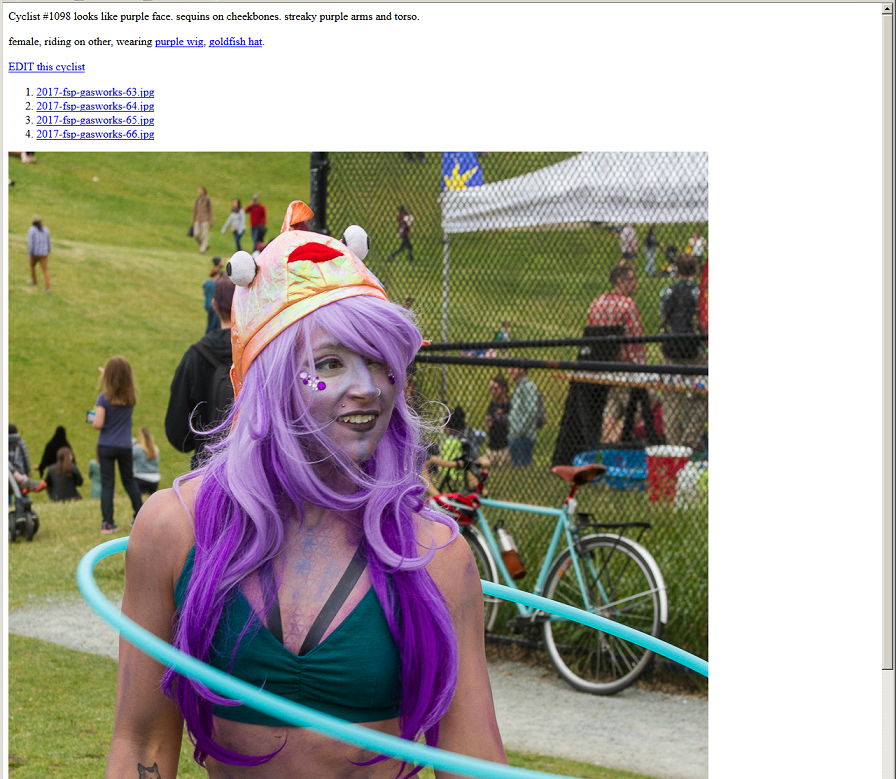
Having a picture of the cyclist on the “view cyclist” page makes it much easier to confirm if I’ve actually found the cyclist I’m looking for, since I can just look between the two images.
The “EDIT this cyclist” page is almost identical to the search/create page, but instead of starting blank, it starts with data filled in from the DB.
Cyclists make multiple laps and groups tend to stick together, so if I see one cyclist back for a second lap, I can look at photographs from her first lap and identify some of the cyclists around her as well.
Preliminary data
I haven’t examined all the photographs yet, but here are some things I’ve discovered so far.
In 2012 photos taken over 50 minutes, I identified 1475 Solstice Cyclists.
Here’s a graph of how many passed over time. Click to expand. 1 pixel vertically = 1 cyclist. 1 pixel horizontally = 1 second. Red represents cyclists on their first lap. Green is the second lap. Blue is the third. There are gaps when my view was blocked, the street was empty, I had to switch memory cards, and when traffic stopped & I paused the automatic camera.

The male/female split is 49/51, even closer than Dragon Con’s demographics, and very different from the split seen in most photographers’ galleries, in which images of women dominate. Hmmmmmm. How curious. HMMMMMM.
1300 people rode bicycles, which is to be expected from a group called the Solstice Cyclists, but I also saw:
- 39 people on foot
- 23 on inline skates
- 6 on roller skates
- 24 on scooters
- 5 unicycles
- 10 people on 5 tandem bikes
- 7 skateboards
- 2 pedicabs, with 2 drivers & 4 passengers
I also identified some groups & popular “costumes”
- 11 giraffes
- 45 mermaids
- 8 Care Bears
- 39 people wearing actual, normal clothes
- 27 Wonder Women
I still have around 700 images to look through, so these numbers will change a bit, but as you can see from the graph, most of the cyclists in these later images are back for another lap, and there aren’t many new cyclists.
Once all that is done, I can start (START!) on the actual meat of this project: creating a grammar for bodypaint based on these thousands of examples & generating new paint patterns.