Preparation
Dwarf Fortress is very complicated, and I often lose track of various projects. In a recent fortress, making steel armor for my soldiers took such a long time. Surely there’s a better way to do it. I decided to speedrun outfiting a full squad of 10 dwarves in steel armor and weapons.
- Each soldier needs:
- weapon 1 bar
- shield 1 bar
- helm 1 bar
- mail shirt 2 bars
- breastplate 3 bars
- gauntlets 1 bar for a pair
- greaves 2 bars
- high boots 1 bar for a pair
- TOTAL: 12 steel bars
I prioritize the metal industry to the exclusion of almost everything else. Dwarves still need food, drink, shelter, and safety or they won’t be able to practice their craft. The world had minerals set to “sparse” instead of “everywhere” so I had to look around for an embark location with iron and a flux layer.
Execution
Once I found a suitable site, I embarked and dug down past the soil and light aquifer to find stone. After a few layers of mudstone, I found limestone! Limestone is a flux stone, which is required to produce steel, so digging my whole fortress out of the stuff was very convienient. As I carved out rooms, I found hematite veins, so there’s my iron ore handled. I dug some exploratory shafts to look for coal, but I never found any, so I had to burn logs into charcoal to power my forges.
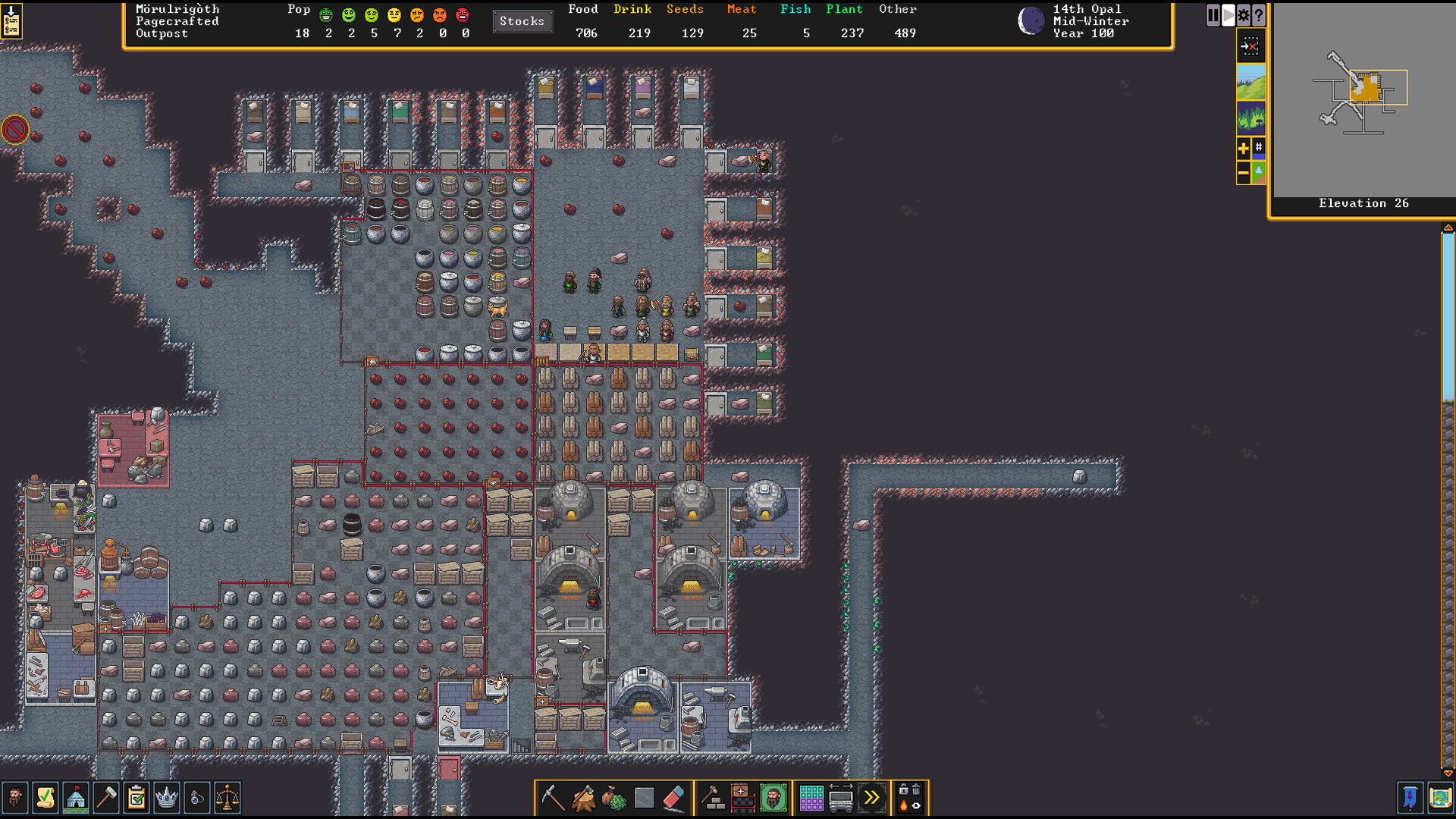
The final fortress fits on one screen if I zoom out a little. I have three Wood Furnaces to turn logs into Charcoal. I’d rather use Bitumenous Coal, which produces 8 pieces of fuel compared to 1 for the logs in the WoodFurnace, but I was spending so much time digging around to find it that I figured chopping down more trees was actually more efficient.
The charcoal feeds three Smelters that turn Hematite boulders into 4 Irons Bars, then turns Iron Bars into Pig Iron, and combines Iron and Pig Iron into steel. I need 120 Steel, so I work backwards to 60 Iron and 60 Pig Iron, so 120 Iron, so 30 Hematite Ore. I set a Work Order to smelt 30 Hematite, then stop. In a normal, ongoing fortress, I’d ask for more Hematite to be smelted whenever I ran short on Iron Bars, but this fort will never need more than 120 Iron Bars.
The Steel Bars are turned into armor and weapons at Metalsmith’s Forges. I have two. One of my migrants was a Legendary Weaponsmith, so he made those 10 spears very quickly. I didn’t have good Armorsmiths, but I assigned each Metalsmith’s Forge to one dwarf who gained a lot of experience and got faster as the project went on.
Craftsdwarves haul ingredients to their workshops, so keeping ingredients close to the workshops means the craftsdwarves spend less time walking and more time craftings. Thus the stockpiles of wood, ore, fuel, metal bars, and finished goods surround the workshops. When I dug out the chamber, limestone boulders were left all over, so I didn’t set up a flux stone stockpile. I later noticed that all those boulders had been used up and craftsdwarves were walking into the mines to get flux stone. I made a flux stone stockpile, so that haulers would spend the time moving rocks, and craftsdwarves would spend their time crafting.
I couldn’t put all my effort into making weapons and armor. My dwarves need to live. I set up a kitchen and still to produce food and drink. I gathered plants from the surface instead of making a farm. I’m not sure that’s more efficient. Any dwarves with spare time can gather plants, but they do have to walk around in the surface to find the plants. I built a small meeting area with tables chairs, and a chest with cups so that dwarves can eat in comfort. The dining hall is separated from the kitchen to avoid miasma from rotten ingredients.
I usually collect gems and cut them at a Jeweler’s Workshop so I can afford lots of items from the merchants in the fall. I put all my effort into the metal industry, so when the caravan arrived, the only things I had to trade were some propared meals and the copper weapons included in our initial equipment. That was still enough to buy all the food the caravan brought. Enough food to get through the winter when we can’t gather on the surface.
At the beginning, I put the Dwarves in a dormitory with 1 bed for every 2 Dwarves. After two migrant waves, I thought they deserved better quarters, so I dug the tiny bedrooms around the edges. I needed beds (must be made of wood) and doors (make them from rock to save wood for charcoal) to create bedrooms. As you can see from the information at the top of the screen, my Dwarves are happy and have plenty of provisions.
I finished forging weapons and armor on the 8th of Granite, six days short of a year since I embarked. But the arbitrary ending condition I set was to have a squad of military dwarves wearing the steel equipment.
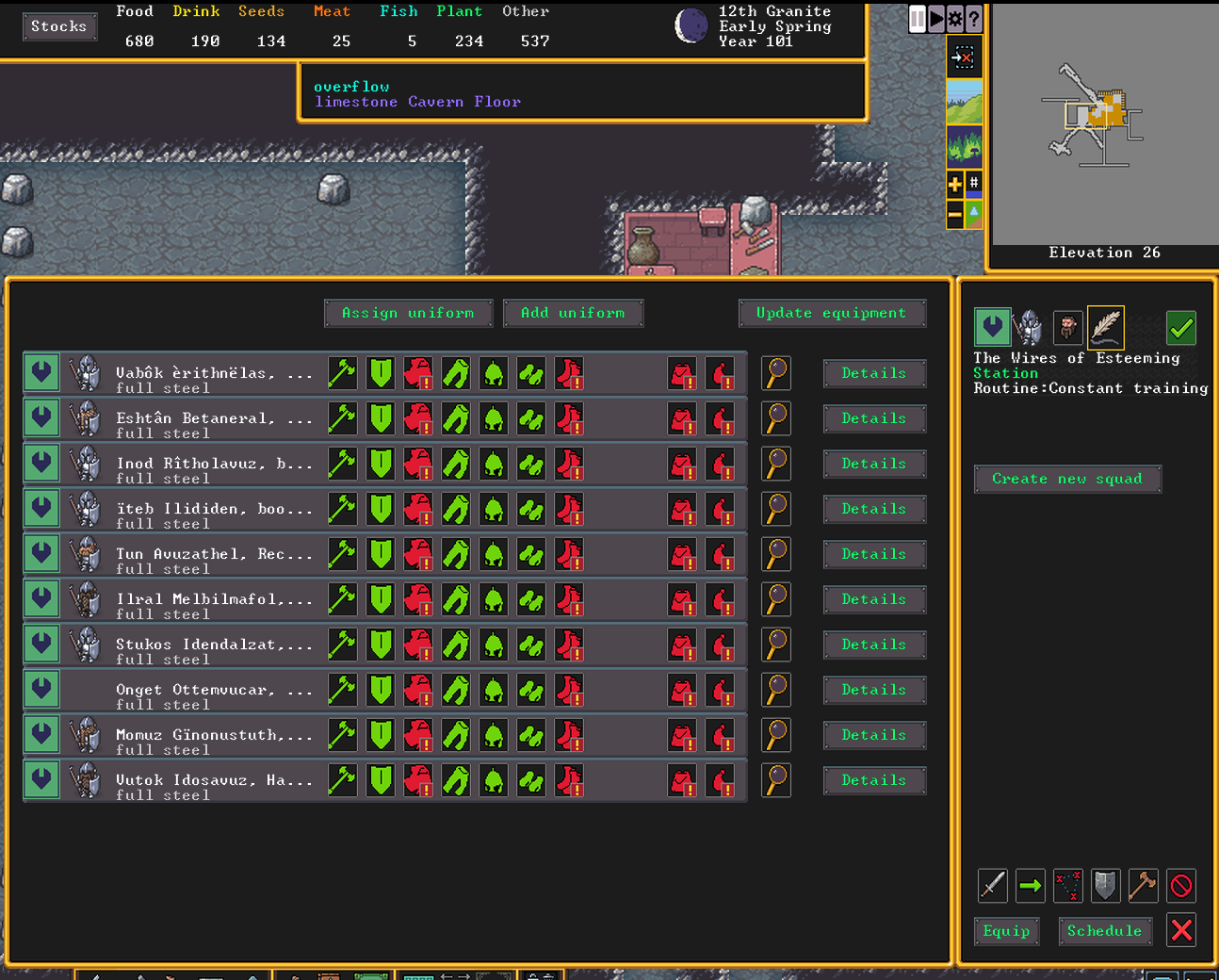
Oh no, why can’t the soldiers find armor or boots? I set the uniform to “replace clothing” and included cloth shirts and socks. Wearing metal armor next to the skin isn’t comfortable. The soldiers will not use the shirts and socks from their civilian wardrobe, and I don’t have ten extra sets.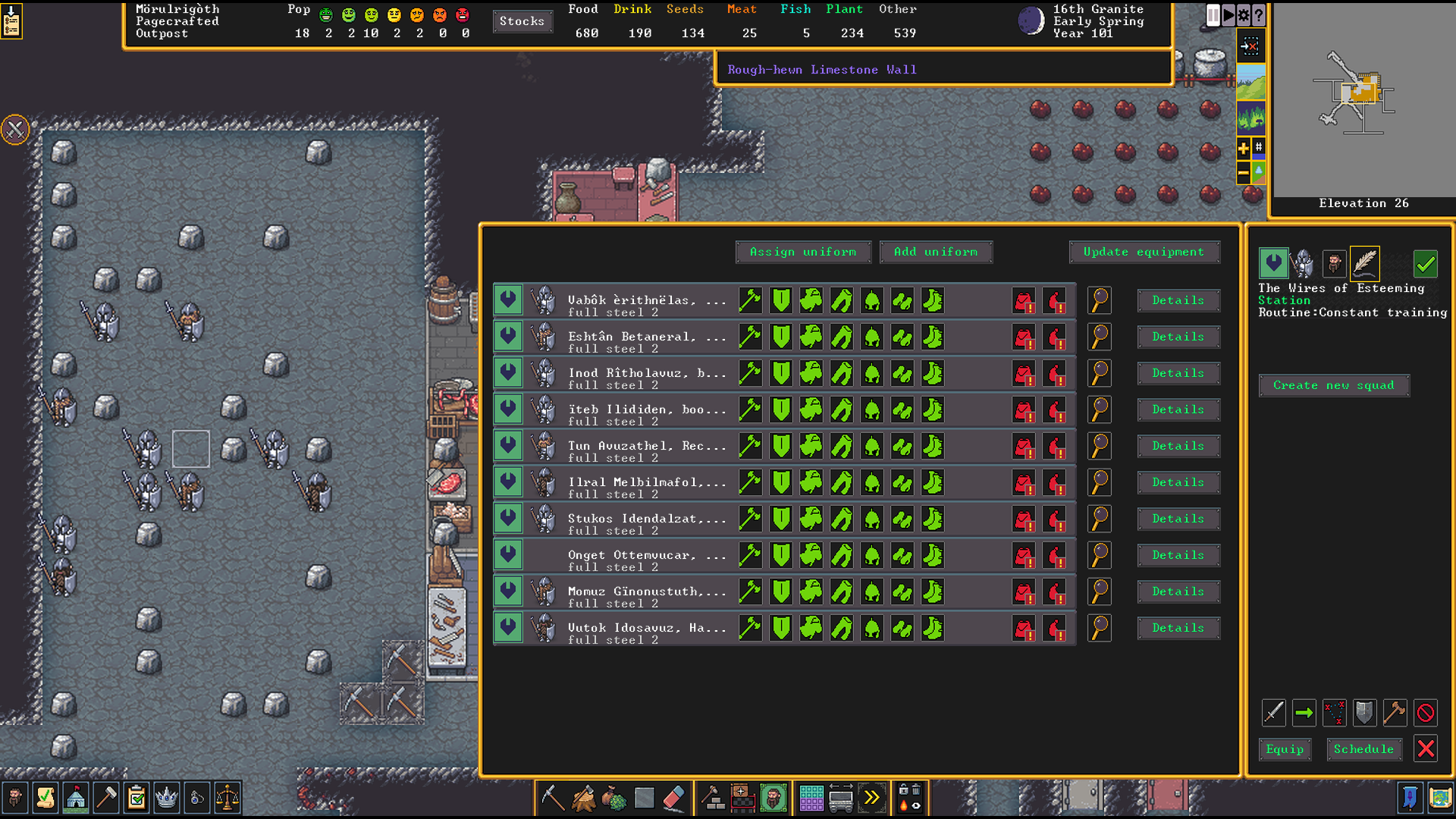
I removed the cloth items from the uniform and set it to “wear over clothing” That makes the soldiers use their civilian clothes to pad their armor. I clicked “update equipment” and ordered the soldiers to gather in a side chamber. Alas, one soldier needed a nap, which delayed the official end of the challenge to the 16th of Granite, 1 year and 2 days after we embarked.
Conclusion
I’m happy with this attempt. One year is a nice benchmark. I didn’t track real time, but I did try to avoid pausing.
There’s a saying (attributed to many different people) that “a racing car should fall to pieces as it crosses the finish line” That means that anything that’s left after the goal is wasted. I could apply that to my fort to make steel production faster. I could put less effort into keeping my dwarves happy, and could make much less food and drink. Like I calculated the amount of ore I needed, I could calculate the total food needed for a year, instead of making more food all the time. An embark location with coal would probably cut out a lot of time. I could build more than 3 Smelters. The production of steel bars was slow enough that only 1 or my 2 smiths built breastplates. The smelters couldn’t make 3 bars of steel before the previous bresatplate was finished.